
Python Scrapy 单页实践
0.目标
https://manhua.dmzj.com/update_1.shtml
1.创建工程
scrapy startproject manhua
2.创建爬虫程序
cd manhua
scrapy genspider manhua manhua.dmzj.com
3.设置数据存储模板(manhua/manhua/items.py)
# -*- coding: utf-8 -*-
import scrapy
class ManhuaItem(scrapy.Item):
#漫画名字。
name = scrapy.Field()
#更新时间。
time = scrapy.Field()
#漫画详情链接。
href = scrapy.Field()
#漫画的唯一标记。
uid = scrapy.Field()
#判断该漫画是否为国漫,1是,0不是。
gm = scrapy.Field()
4.编写爬虫(manhua/manhua/spiders/manhua.py)
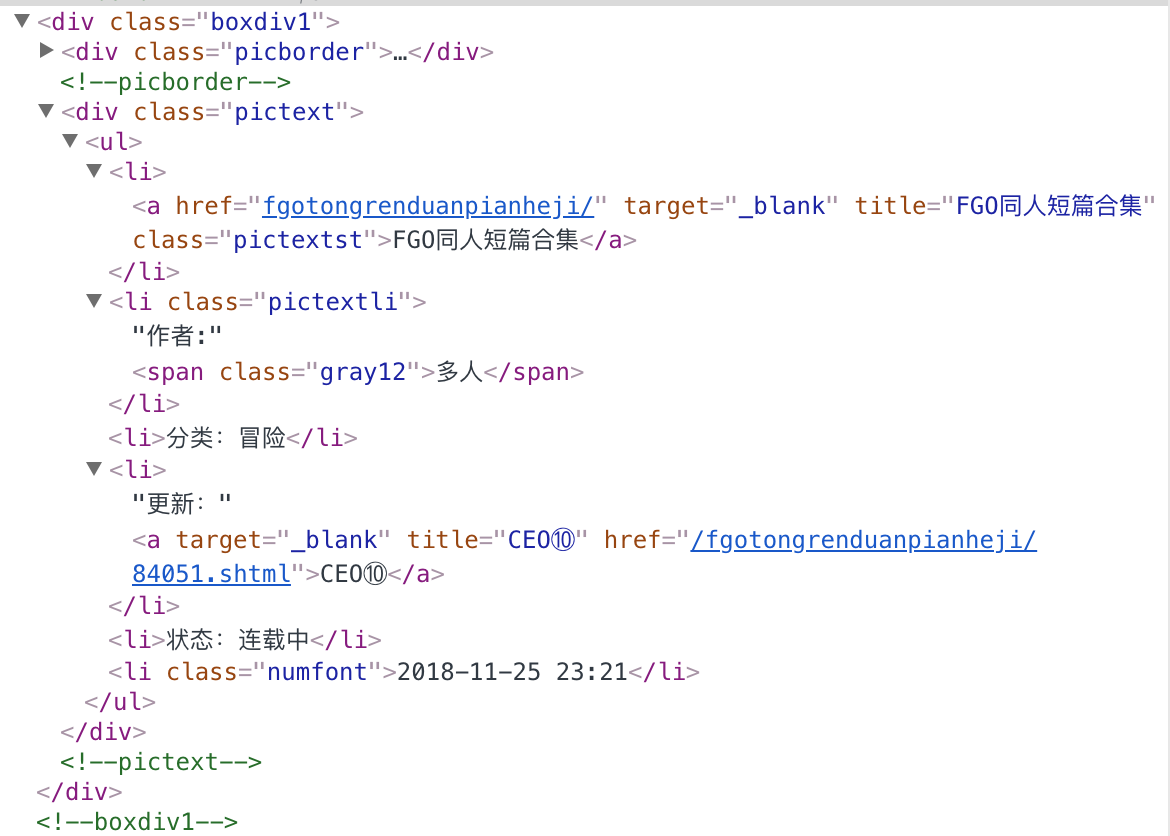
非国漫的数据格式


国漫的数据格式


偶尔数据格式会有所不同,比如时间,或者作者之类信息不同。

爬虫
# -*- coding: utf-8 -*-
import scrapy
from manhua.items import ManhuaItem
class MahuaSpider(scrapy.Spider):
name = 'mahua'
allowed_domains = ['manhua.dmzj.com']
start_urls = ['https://manhua.dmzj.com/update_1.shtml']
def parse(self, response):
manhuas = response.xpath('//div[@class="boxdiv1"]')
for manhua in manhuas:
item = ManhuaItem()
#获取名字
item['name'] = manhua.xpath('./div[@class="picborder"]/a/@title').extract()[0]
#获取链接
tempHref = manhua.xpath('./div[@class="picborder"]/a/@href').extract()[0]
tempHrefArr = tempHref.split('/')
#通过链接长度判断
if len(tempHrefArr) == 2:
#非国漫的
item['uid'] = tempHrefArr[0]
item['gm'] = 0
#item['href'] = "https://manhua.dmzj.com/" + tempHrefArr[0]
else:
#国漫的
#item['href'] = tempHref
item['gm'] = 1
tempUid = tempHrefArr[len(tempHrefArr) - 1]
tempUidArr = tempUid.split('.')
if len(tempUidArr) == 2:
item['uid'] = tempUidArr[0]
else:
item['uid'] = tempUid
#获取时间
test_time = manhua.css('div.pictext > ul > li.numfont > span::text')
if test_time:
item['time'] = test_time.extract()[0]
else:
item['time'] = manhua.css('div.pictext > ul > li.numfont ::text').extract()[0]
yield item
5.管道处理(manhua/manhua/pipelines.py)
# -*- coding: utf-8 -*-
import codecs
import json
class ManhuaPipeline(object):
def process_item(self, item, spider):
with open("my_manhua.txt", 'a') as fp:
fp.write(item['name'].encode("utf8") + '\n')
fp.write(item['time'].encode("utf8") + '\n')
fp.write(item['uid'].encode("utf8") + '\n')
fp.write(item['gm'] + '\n\n')
class JsonPipeLine(object):
def __init__(self):
self.file = codecs.open('test.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
ManhuaPipeline 将会把数据保存为 txt 文件,如:

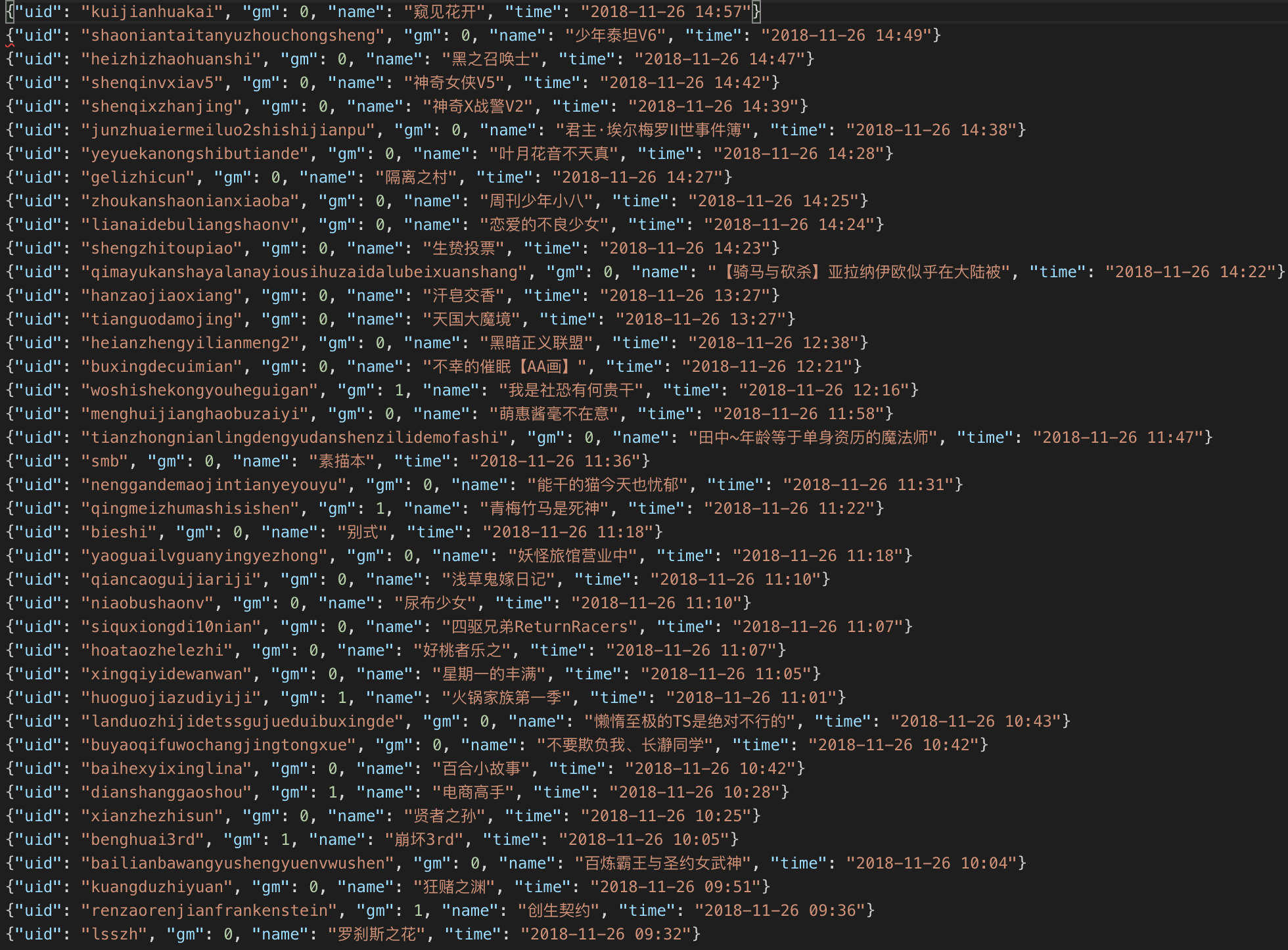
JsonPipeLine 将会把数据保存为 json 文件,如:
6.设置配置管道(manhua/manhua/settings.py)

67行至70行,默认是屏蔽的,当然是没有69行的存在,默认内容就是68行。
配置项目的管道,使它执行管道(manhua/manhua/pipelines.py)上的内容。
7.执行爬虫
cd manhua
scrapy crawl manhua
假如使用:
scrapy crawl manhua -- nolog
将不会看到过程输出的信息。